LLMファインチューニングを劇的に高速化!「Unsloth Studio」完全解説

- AI技術
- LLM
近年、Llama 3やMistralといった高性能なオープンソースの大規模言語モデル(LLM)が登場し、企業や個人が独自のデータでモデルを再学習(ファインチューニング)するニーズが高まっています。しかし、LLMのファインチューニングには、膨大な計算資源(GPUメモリ)と時間が必要であり、これが大きな参入障壁となっていました。
この問題を解決し、LLM開発の民主化を推し進める画期的なツールとして注目を集めているのが「Unsloth Studio」です。本記事では、Unsloth Studioの概要、劇的な高速化を実現する仕組み、そして具体的なメリットについて詳しく解説します。
1. Unsloth Studioとは?
Unsloth Studioは、オープンソースのLLMファインチューニング高速化フレームワーク「Unsloth」をベースとした、LLM開発のための統合プラットフォームです。
Unsloth自体は、Hugging Faceエコシステム(Transformers, PEFT, TRLライブラリ)の上に構築された最適化ライブラリであり、Llama 3, Mistral, Gemmaなどの主要なオープンソースモデルの学習速度を2倍〜5倍にし、メモリ使用量を最大70%削減することを可能にします。
Unsloth Studioは、この強力な最適化技術をより使いやすく、そして包括的に提供することを目指しています。
2. なぜこれほど速いのか?その仕組み(図解)
Unslothが劇的な高速化とメモリ節約を実現している理由は、単一の技術ではなく、複数の高度な最適化を組み合わせている点にあります。
標準的なPyTorchやHugging FaceのTransformersライブラリは汎用性を重視していますが、Unslothは特定のモデルアーキテクチャ(特にLlama系)に対して、ハードウェアレベルに近い部分で徹底的なチューニングを行っています。
以下は、標準的なファインチューニングとUnslothによる最適化の違いを概念的に示した図解です。
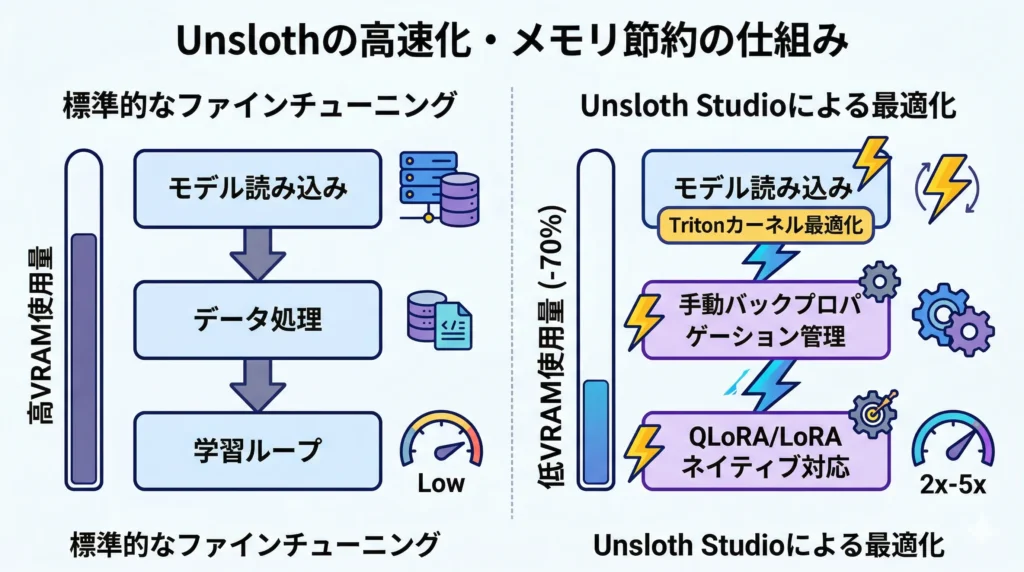
Unslothの高速化・メモリ節約の仕組みには、以下の主要な最適化が含まれます。
A. Tritonカーネル最適化
OpenAIが開発した言語「Triton」を使用して、GPUカーネル(GPU上で実行されるプログラム)を独自に最適化しています。特に、LoRA(Low-Rank Adaptation)に関連する計算、例えば線形層の量子化や、特定の活性化関数(RoPE, SiLUなど)の処理において、標準的なPyTorchのカーネルよりも遥かに高速な実装を行っています。
B. 手動バックプロパゲーション管理
通常のPyTorchでは、自動微分(Autograd)システムが勾配計算をすべて自動で行いますが、これはメモリを多く消費します。Unslothは、LoRAの勾配計算を「手動」で管理し、メモリの使用を最適化しています。これにより、特定のモデルに対して、標準的なTransformersライブラリよりも劇的に少ないメモリで学習可能になります。
C. QLoRAへのネイティブ対応
Unslothは、4ビット量子化(QLoRA)にネイティブで対応しています。これにより、GPUメモリをさらに大幅に節約でき、通常では学習不可能なモデル(例えばLlama 3 70B)を、一般的なコンシューマ用GPU(例: 24GB VRAMのNVIDIA A10GやA100)でも学習可能にします。
3. Unsloth Studioを利用するメリット
Unsloth Studioを利用することで、LLM開発者は以下のような具体的なメリットを得られます。
A. 学習時間の劇的な短縮
学習時間が2倍〜5倍に短縮されることは、単に「待つ時間が減る」だけではありません。開発のイテレーション(試行錯誤)のサイクルを劇的に速め、より多くの実験を行い、短期間でより高品質なモデルを構築することを可能にします。
B. 計算コストの削減
学習に必要なGPUメモリが最大70%削減されるため、高価な多GPU環境(例: 8x A100)を用意する必要がなくなります。24GB VRAMのシングルGPU、あるいは無料枠を含むGoogle ColabやKaggle NotebooksでもLLMのQLoRAファインチューニングが可能になり、計算コストを大幅に削減できます。
C. 既存エコシステムとの互換性
Unslothは、Hugging Face Ecosystem(TRL, PEFT, Transformersライブラリ)と完全な互換性を保っています。既存のファインチューニングスクリプトを、わずか数行の変更でUnslothに移行することが可能です。
D. サポート対象の拡大
Unsloth Studioは、Llama 3, Mistral, Gemma, Phi-3, Qwen 2など、主要なオープンソースモデルのアーキテクチャに対して広く最適化を提供しています。また、これらのモデルをQLoRAだけでなく、LoRAや通常の全パラメータファインチューニングでも高速化できます。
4. まとめ:LLM開発の民主化を加速する存在
Unsloth Studioは、これまで一部の巨大企業や研究機関しか手が出せなかった「高性能なLLMのファインチューニング」を、劇的な高速化とメモリ節約によって、より多くの開発者や中小企業に開放する存在です。
特に、Llama 3やMistralなどの強力なベースモデルが登場した今、Unsloth Studioを活用して、独自のデータで、かつ低コストで高性能なAIを構築することは、企業にとって強力な競争力となり得るでしょう。LLM開発の未来は、Unslothによって、よりアクセスしやすく、より効率的なものへと変わりつつあります。